I wonder if any techie here can give me a suggestion.
I’m creating about 100 text files on a server. The files are in Japanese. I think they might be ISO-2022-JP encoded but I’m not sure. If they were UTF-8 there probably wouldn’t be this problem.
If I download the files as .txt and open them they look like garbage.
If I upload the files to my Google Drive and open them in Preview there they look fine there.
If I open them in Google Docs they look fine.
If I save them as Google Docs and download them to my Mac as Word files they look fine on my Mac when I open them with Word. So Google Docs is able to figure out what the encoding or whatever issue there is and fix it.
But if I try to not use Google Docs (it’s an extra 100+ steps to go that route) and open them directly with Word on my Mac it just causes a bunch of errors and they won’t open.
This would be ok if not for the fact that in Google Drive you can only open one file at a time. I’d like to be able to select all 100, save all 100, then download all 100 and be done with it but I can’t.
I’m open to any reasonable suggestion. Like even figuring out how to fix the encoding on my Mac and open it with just an ordinary text editor. I usually use BBEdit, but selecting different languages doesn’t seem to fix the contents. Going via Google Docs is one of the only things that fixes it.
Another round-about fix is to edit the garbage-looking file, replace all line endings with , and change the filetype to .html. Then if I double-click on it it will open in Chrome and look fine. That is also another sort of acceptable alternative if there isn’t anything more straightforward. And I guess that saves me having to upload and download the Word files. But it’s something that would have to be done 100+ times. Plus Word files can at least be edited. A web page can’t.
If you open the file in Safari, you can then go to the View → Text Encoding menu to manually select the text file encoding.
Once you select the correct encoding (so everything renders OK), see if you can copy/paste the contents into TextEdit or something else that can save into UTF-8 format.
If you are a user of the Emacs text editor, you can put a line at the top of a text file specifying the file’s encoding. Emacs will use this whenever the file is loaded in order to configure its own display, although it may have no impact on any other apps.
For instance, I put this on top of text files created on Windows systems (which tend to use Microsoft’s extension to the Latin-1 encoding):
-*- coding: windows-1252 -*-
You can, of course, replace the windows-1252 with the encoding your file uses. The Emacs command list-coding-systems will show you everything your installation supports:
###############################################
# List of coding systems in the following format:
# MNEMONIC-LETTER -- CODING-SYSTEM-NAME
# DOC-STRING
M -- mac-roman
Mac Roman Encoding (MIME:MACINTOSH).
c -- chinese-iso-8bit (alias: cn-gb-2312 euc-china euc-cn cn-gb gb2312)
ISO 2022 based EUC encoding for Chinese GB2312 (MIME:GB2312).
U -- utf-8 (alias: mule-utf-8)
UTF-8 (no signature (BOM))
B -- chinese-big5 (alias: big5 cn-big5 cp950)
BIG5 8-bit encoding for Chinese (MIME:Big5)
J -- iso-2022-jp (alias: junet)
ISO 2022 based 7bit encoding for Japanese (MIME:ISO-2022-JP).
S -- japanese-shift-jis (alias: shift_jis sjis)
Shift-JIS 8-bit encoding for Japanese (MIME:SHIFT_JIS)
Z -- euc-tw (alias: euc-taiwan)
ISO 2022 based EUC encoding for Chinese CNS11643.
E -- japanese-iso-8bit (alias: euc-japan-1990 euc-japan euc-jp)
ISO 2022 based EUC encoding for Japanese (MIME:EUC-JP).
E -- euc-jis-2004 (alias: euc-jisx0213)
ISO 2022 based EUC encoding for JIS X 0213 (MIME:EUC-JIS-2004).
K -- korean-iso-8bit (alias: euc-kr euc-korea)
ISO 2022 based EUC encoding for Korean KSC5601 (MIME:EUC-KR).
1 -- iso-latin-1 (alias: iso-8859-1 latin-1)
ISO 2022 based 8-bit encoding for Latin-1 (MIME:ISO-8859-1).
- -- us-ascii (alias: iso-safe)
Encode ASCII as-is and encode non-ASCII characters to `?'.
...
Here is a possible way to deal with all the files at once. Note that this will only work on text files, not formatted files such as RTF. Also, all or most of the files should have the same encoding.
Create an empty folder called Test1 in your Downloads folder.
Copy (do not move) all the Japanese text files to Test1. In this way we ensure the integrity of the original files.
Again, please ensure that you have a backup of the original files.
We will use the iconv command to convert the files to UTF-8 format.
Open Terminal.
Issue the following commands. The easiest way to do this is to copy the next three lines including the final newline and paste them into Terminal.
test1=$HOME'/Downloads/Test1' enc='ISO-2022-JP' for file in $test1/*; do iconv -f $enc -t UTF-8 "$file" > "${file%}_NEW"; done
If the last line just seems to sit there, hit the return key.
You will now have updated files with “_NEW” appended.
I tested this on Japanese files encoded with ISO-2022-JP in a bash shell in Terminal. I also tested a file with spaces in the filename, just to be safe. According to BBEdit, the new files are UTF-8 encoded.
If you need to try a different encoding, remove the “_NEW” files from the folder and reissue the second line with a different encoding:
Obviously, you need to know what it is before you can convert it.
Have you tried to open it in Safari? Then select various encodings from the menu bar until you find one that renders the text correctly. Once you know what the encoding is, it should (hopefully) not be hard to convert it.
This is a bit of manual work, but hopefully all the documents are using the same format, so you can use what you learned from one and apply it to the rest.
Now that you know it is Shift-JIS, you can use @garyk’s script with it:
test1=$HOME'/Downloads/Test1'
enc='SHIFT_JISX0213'
for file in $test1/*; do iconv -f $enc -t UTF-8 "$file" > "${file%}_NEW"; done
Or maybe
test1=$HOME'/Downloads/Test1'
enc='SHIFT_JIS-2004'
for file in $test1/*; do iconv -f $enc -t UTF-8 "$file" > "${file%}_NEW"; done
If you’re lucky, it will work for all the files. If not, then keep the good results for those files that successfully converted and try a different encoding for the rest. Repeat until you’re done.
Back to here, using the Safari test recommended above I was able to see that the contents were apparently Shift JIS. According to iconv SHIFT-JIS is one of the encodings allowed so I tried:
MacBook-Pro:Test1 admin$ test1=$HOME'/Downloads/Test1'
MacBook-Pro:Test1 admin$ enc='SHIFT-JIS'
MacBook-Pro:Test1 admin$ for file in $test1/*; do iconv -f $enc -t UTF-8 "$file" > "${file%}_NEW"; done
So I’m not sure what to do right now except convert all the files to .html and just open them in Chrome, or go through the Google Docs upload and download procedure 100 times.
Any more ideas? This has been useful so far! Thanks.
Interesting. This morning I find I can open the .txt file with Word on my Mac, choose the default view with their preview, and “save as Word file” works and can open and show the Japanese.
So I can avoid the excessive uploads/downloads with Google Docs.
So I wonder if there is way of doing this en masse…
Anyway, I put my mind on hold for a couple of hours and opened them all in Word on my Mac.
Of the 116 files, 46 did not convert to proper Japanese. Of the ones that did, most were done rather quickly.
The rest I uploaded to Google Drive and opened them in Google Docs. Google Docs was able to preview all the ones that Word could not. I was able to open 41 of the 46 in Google Docs and download them, so they are done.
The 5 remaining on Google Drive I don’t know what to do with. They preview fine, but when I try to open them it’s just taking forever. These are the 5 largest files though. The .txt versions range from 2.5 MB to 7 MB. Could it just be taking Google Docs an ungodly amount of time to open them? I started over again and am trying them one at a time. If that doesn’t work I’m just going to do that convert-to-HTML trick with the 5 that are left and view them in Chrome when needed.
I would be very interested in getting the iconv feature to work though. It looks quite useful.
From the “8th-anniversary.txt:367:0:” portion of the error message, I am guessing that iconv ran into a problem around byte 367. Perhaps the start of the file had ASCII text which then changed to Japanese text.
As mentioned above try enc='SHIFT_JISX0213' instead of enc='SHIFT-JIS'. Although the iconv --list command shows SHIFT-JIS as part of the output, that specific text is not in the leftmost column.
One other thought that I had was that some of your files may have been RTF or RTFD and then lost the extension. The size of the remaining files hints at images. It may be worth a try simply to append .rtf or .rtfd and then try opening the file in TextEdit.
Right-clicking on a problem file and noting what appears in the “Open With” entry of the popup may also give a clue.
To find out more about iconv, enter info iconv in Terminal. Use the space bar to scroll through the entry, and control-z to exit.
I usually use BBEdit, but selecting different languages doesn’t seem to fix the contents.
in BBEdit it just says “Western” at the bottom.
Just to clarify something – my apologies if you’re already doing this – but BBEdit has two lots of overlapping settings for encoding.
What shows up at the bottom of the window in the encoding pop-up menu is the encoding BBEdit is currently using, based on a combination of the file’s last specified encoding, BBEdit’s defaults, and BBEdit’s best inference from the contents. (You can prioritize your own list of fallback encodings in Preferences.)
If you change that encoding, what it does is take the current contents as displayed (even if they’re wrong) and transform them into the encoding you select. (If you then save the file, those changes become permanent.)
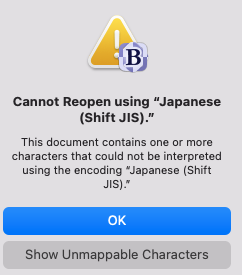
If you want BBEdit to try re-interpreting an opened file under a different encoding, you have to use the “File ▸ Reopen using Encoding” command.
Thanks for that info. I never noticed that before. I just tried it with one that coverts ok in Word on my Mac and this dialog popped up.
Weird.
I think/hope this is just a one-time situation dealing with a bunch of pre-UTF-8 Japanese characters from a server, but I have to admit I’m still curious.
The start of the file was, indeed, English ASCII that said
----Public Discussions----
For now I’m done with those files, and as mentioned in my other post I hope I don’t run into this again. I was exporting discussion forums from a site using old, pre-UTF-8 encoding and the exporter itself exported in G-d know what.
There were no images exported though. Some of the files represent discussion topics and replies in groups where there was lots of activity over many years and they had hundreds of different topics. So it makes sense that the file containing the discussions was that large.
For now, for the 5 I was not able to convert, I did this:
Open in BBEdit.
Replace the line endings with
Change the extension from .txt to .html
After doing that, double-clicking on in opens it in Chrome (my default browser) and you can see all the Japanese perfectly. As an extra test I also tried these browsers:
Safari: won’t open it and reports an error instead.
Firefox: looks like it does in BBEdit or the default Text editor - garbled text.
Edge: works also
Google Support tried to help by the way, but after an hour we were not able to figure out why those 5 files only would not open in Google Docs when the others all would.
I will, just to know, try some of the tests you mentioned.